February 05, 2016

Robot Exclusion Protocol or Robots.txt file is believed to be an important aspect of a website. This file provides instructions to the search engine spiders on what the entire site comprises for them to crawl.
Many SEO consultants designate the robots.txt file as an essential factor for effective SEO strategy, and if not used properly then it can affect visibility on search engine results page. In this article, we are going to dig robots.txt file in depth and find out - how these file performs for effective SEO mechanism.
For beginners – What is robots.txt?
Any webmaster tool, no matter whether you are using a paid version or free, knows the importance of robots.txt files for SEO. This file encloses a set of instructions for search engine spiders, giving information about those sections of your website, which you don’t wish to be crawled. If these files are not used appropriately, then it can lead to a negative impact on the search engine visibility of your website.
How does it work?
When the search engine spiders crawl your website, the very first thing they search is the robots.txt file. As we have already mentioned, this file gives the crawlers certain instruction about their crawling areas across the website. It clearly states about those segments which are not allowed to index and crawl for search engine results page.
To locate the robots.txt file of any site, simply add robots.txt at the end of the domain name, as shown in the figure.

After receiving the instructions from robots.txt file, the search engine spiders follow them and do not consider the mentioned areas for crawling and indexing.
How robots.txt file helps?
There are various reasons for robots.txt file helps a website. We have listed all the reasons below:
If you have duplicate content at your website, the robots.txt files contribute in no crawling mechanism for those pages.
If your website comprises internal search functions, then you can exclude those functions from crawling by including those areas into the robots.txt file.
You can also provide instructions to the search engine spiders to avoid protected segments of your website.
When search engine spiders crawl a website, they also access XML sitemap. The XML sitemap embraces the array of all locations which should be crawled in a website. This tool contributes in improvising the crawling mechanism.
How to create the robots.txt file?
If your website is running without a robots.txt file, then it is highly advised to create a one. It is considered as an important aspect for a website. You can take help from a technical resource, or if you have enough knowledge about development, then you just need to follow the below steps:
Step #1: Create a new text file with notepad in windows or TextEdit in Macs and then save the file with "robots.txt" file name.
Step #2: Upload the file at the root directory, which helps the file to appear after the domain name.
Step #3: If you access subdomains, then you are required to make robots.txt file for every subdomain.
Simple robots.txt file
The first line in file signifies for which agent (Search Engine Spider), the rule applies for. For example, User-agent: * indicates that the rule applies for every search engine spider.
The next line indicates the path, which are allowed or not allowed to index or crawl.
In robots.txt file, different instructions for different crawlers can also be included, but it should be in sequence.
Examples of robots.txt file
Further, we have shown some examples of robots.txt files. Have a look:
This file allows the search engine spiders to crawl everything, available on a website.

This file allows Google crawlers to crawl and index everything on the website and blocks the site for other search engines.

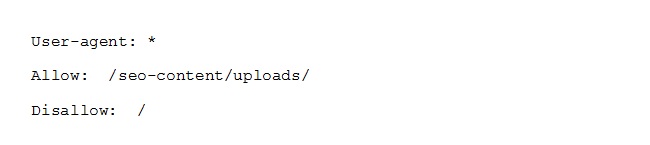
The following file enables the spiders to crawl and index all the files that are available in “seo-content” folder, but nothing else.

This file gives instructions to block Google from indexing URLs by using the query parameter.

The following file enables all crawlers to get blocked from a specific file.

In case you are seeking for more information about the robots.txt file, then you can search for professional SEO Company in your city. For example, type Atlanta SEO Company on Google if you live in Atlanta, and get list of many professional service providers.
Recent Posts


























ARE YOU A LEADING SEO SERVICE PROVIDER?
Get listed in world's largest SEO directory today!
Directory listing counter is continuously increasing, be a part of it to gain the advantages, 10386 Companies are already listed.
