January 07, 2016

It’s so surprising right, that search engines analyze, index and provide ranked pages. Have you ever think, how it does everything? How it found canonical and follow the process. To make it clear for people with very basic understanding, let’s find how search engines crawl pages and add links to the link graph?
We can call it a spider for simple imagination. So, the search engine crawler visits a site and collects the files of the format, which it access. Like, the first thing it collects is the robots.txt file.
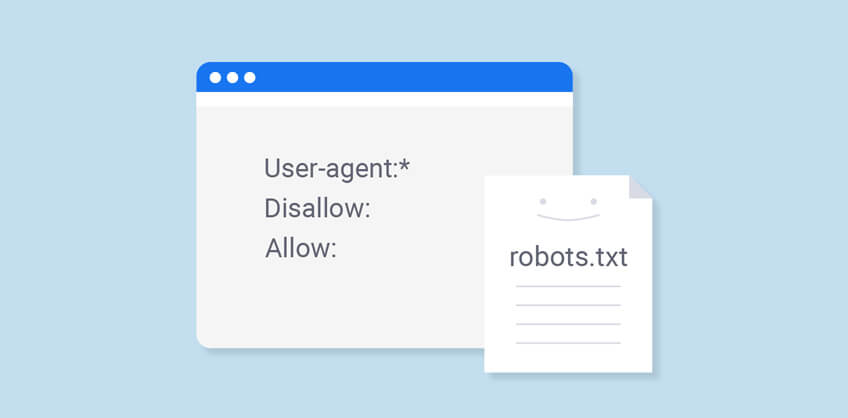
Only cases there are, either the file exists or it will not be. SO, the search engine has to crawl the whole site. The crawler collects information about all of those pages and feeds it back into a database. Strictly, it’s a crawl scheduling system that de-duplicates and shuffles pages by priority to index later. As gets the file, it makes a list of links corresponding all those pages. It the links are internal, the crawler will probably follow them to other pages. On the contrary, if they are external then it will put them into database, to be accessed whenever required.
Then after, it processes the links with the help of link graph. Search Engine pulls all the links from the database and connects them. It assigns a relative value, called indexing; it can be both positive and negative.
The link, which is scored fairly, gets high rank while the link, which gets low scored, ranked low.

If considering a situation, where the file told the search engine not to access one of the pages. So, when the link graph access and search engine process all the links from database. It connects them and assign some relative value. Now, if one of the pages is spammed then it will be passing some bad link value on to those pages.
Thus, search engine process links to give best but other factors also work to improve the results. A SEO depends on number of ranking factors called success factor for its success.
Recent Posts


























ARE YOU A LEADING SEO SERVICE PROVIDER?
Get listed in world's largest SEO directory today!
Directory listing counter is continuously increasing, be a part of it to gain the advantages, 10362 Companies are already listed.
